Claude 3.7 Sonnet 深度解讀: 重新定義AI程式設計能力和推理模型
URL Source: https://mp.weixin.qq.com/s/3iTV3IFUPMYT3pXrKiYWgw?token=2234161&lang=zh_CN
Mathematics is a way of understanding the world, but it is not the world itself.
數學是我們理解世界的一種方式,但並不是世界本身。
理查德·費曼(Richard Feynman)

今天凌晨,Anthropic 的新模型 Claude 3.7 Sonnet 釋出。如果只用一句話總結的話,那就是:現實軟體工程的 AI 程式設計能力又得到了一大突破,你可以在 Cursor 等 AI 程式設計工具中無腦選擇使用這個模型,並且放棄任何沒有接入這個模型的 AI 程式設計工具。
從 AI 程式設計的正規化來看,上一個臨界點發生在 2024 年 6 月。那時 Claude 3.5 Sonnet 讓 AI 程式設計能力有了質的飛躍,讓 Cursor 這個打磨了一年多的 IDE 產品得以起飛進入大眾視野,並且 Claude 3.5 Sonnet + Cursor 這種組合讓 AI 程式設計真正突破了“可用性臨界點”,讓 0 基礎不會寫程式碼的人也可以嘗試透過 AI 程式設計創造產品,享受創造的魔法。
從去年 6 月至今,你可能在無數新模型釋出的 benchmark 中看到它們如何超越 Claude 3.5 Sonnet,比如 OpenAI 的 o1、o3,DeepSeek V3、R1,Grok 3 等等。但現實是,真正在使用 AI 程式設計工具寫程式碼、開發產品的人都會感受到,Claude 3.5 Sonnet 才是這期間唯一最好的程式設計模型。
這個結論可能有點反直覺,但我想跟你說說為什麼。
程式設計競賽和軟體工程��是兩回事
大多數 AI 模型在釋出時,都會用 Codeforces 這樣的評估標準來衡量程式設計能力。Codeforces 是一個國際程式設計競賽平臺,你可以把它理解為“演算法比賽”,類似奧數競賽,但面向電腦科學領域。
但……你應該能理解,程式設計競賽和現實世界的軟體工程壓根就是兩回事。
拿奧數舉例,獲得奧數金牌的人,未必會成為數學家,甚至不一定會在數學領域深耕。現實世界裡,各大網際網路公司的 CTO、頂級架構師,大多數都不是靠程式設計競賽出身的。
同樣,一個 AI 模型在 Codeforces 裡刷高分,證明的是它在演算法推理、數學計算上的能力,但不代表它能幫你開發一個真正能跑的 Web 應用,更不代表它能維護一個百萬行程式碼的企業級專案。
Codeforces 為什麼成為 AI 程式設計能力評測的主流?
原因很簡單:它夠標準化,夠簡單,也夠容易最佳化。
一個 AI 模型要想在 Codeforces 競賽中拿高分,本質上就是提升它的數學推理能力、演算法最佳化能力,以及程式碼補全能力。這些能力可以透過調整訓練資料、最佳化推理策略來提升,而評測標準也是客��觀的——程式碼跑不跑得通,耗時多少,結果對不對,這些都可以量化。
而 Codeforces 的任務,往往是自包含的、無上下文依賴的、單檔案程式碼,AI 只需要專注於寫出一個正確的演算法,而不需要考慮程式碼如何融入到一個已有的程式碼庫裡,不需要關注軟體架構,也不需要管理依賴關係。
對於大模型來說,這種任務很好最佳化。只要你給它提供足夠多的程式設計競賽題,讓它大量練習,它的 Codeforces 得分自然會不斷上升。
這也是為什麼,我們會看到 OpenAI、DeepSeek、xAI 等廠商在新模型釋出時,都會強調“我們的 AI 在 Codeforces 上又超越了Claude 3.5 Sonnet了!”——因為這個 benchmark 的分數最容易提升。
但問題是,這真的對現實世界的 AI 程式設計能力有參考價值嗎?
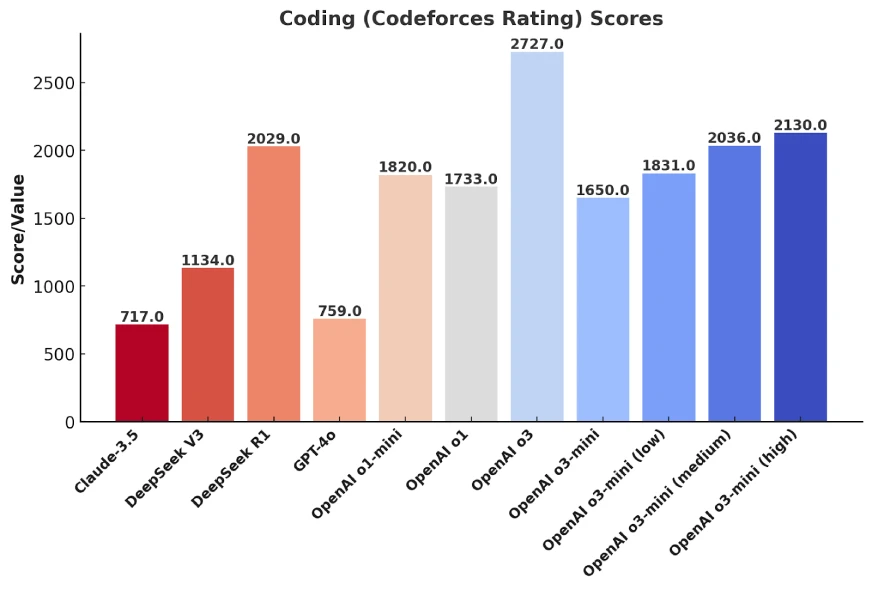
為什麼 Codeforces 分數高 ≠ 現實軟體工程能力強?
如果你真正在用 AI 寫程式碼,你應該已經發現了 AI 程式設計的幾個典型問題:
-
它可以寫出一段完美的演算法,但你讓它在一個大型專案裡修 Bug,它可能連程式碼庫的結構都搞不清楚。
-
它可以在幾秒鐘內寫出一份精妙的動態規劃解法,但你讓它最佳化資料庫查詢,它可能直接生成一段低效 SQL。
-
它能寫 Leetcode Hard 級別的程式碼,但你讓它改一個前端 UI 元件,它可能會完全無視設計規範,寫出一堆拼湊出來的 CSS。
這些問題,都不是 Codeforces 能測出來的,因為 Codeforces 評測的是“一個獨立演算法任務能不能解出來”,而軟體工程關心的是“這個程式碼能不能在一個龐大的程式碼庫里正常執行”。
換句話說,AI 在程式設計競賽上贏過 99.9% 的人類了,但它依然不能替代現實世界的程式設計師。
真正衡量 AI 程式設計能力的標準:SWE-bench 和 SWE-Lancer
如果 Codeforces 不能反映 AI 程式設計的真實能力,那什麼可以?
目前有兩個更值得關注的評測標準:
- SWE-bench Verified(衡量 AI 修 Bug 能力)
- SWE-Lancer(衡量 AI 在真實軟體工程任務中的表現)
SWE-bench Verified:AI 真的能修 Bug 嗎?
SWE-bench Verified 不是讓 AI 解演算法題,而是讓它去修真實的軟體 Bug。
這些 Bug 都來自開源專案,AI 需要在不破壞原有程式碼的前提下修復它們,並透過自動化測試驗證修改是否正確。換句話說,這是在模擬現實世界的程式碼維護工作。
在這個測試裡,Claude 3.7 Sonnet 拿到了 70.3% 的成功率,比 Claude 3.5 、OpenAI o1、o3-mini、DeepSeek R1都提升了 20%以上,這完全是研發級的勝利。
這意味著,Claude 3.7 已經可以在大多數情況下,穩定地幫你修復程式碼錯誤,而不像以前的 AI 那樣,修完 Bug 可能還得你自己再修它留下的新 Bug。
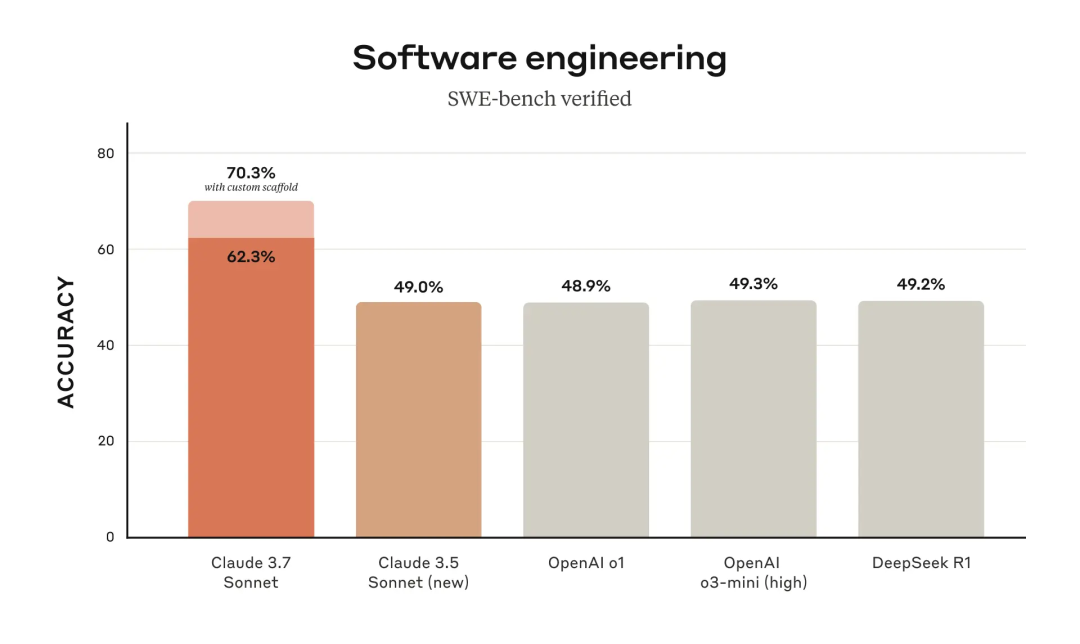
SWE-Lancer:AI 在真實軟體開發中的競爭力
SWE-Lancer 是 OpenAI 提出的一個新評測標準,它直接從自由職業者平臺 Upwork 裡選取了 1488 個真實的軟體開發任務,總價值 100 萬美元,然後讓 AI 去競爭這些任務,看它能不能完成並“賺到錢”。
任務分成兩類:
- IC SWE(獨立開發者任務):AI 需要像自由職業者一樣,真正開發功能、修復 Bug。
- SWE Manager(技術管理任務):AI 需要評估多個開發者提交的方案,並選擇最優解,相當於扮演“技術負責人”。
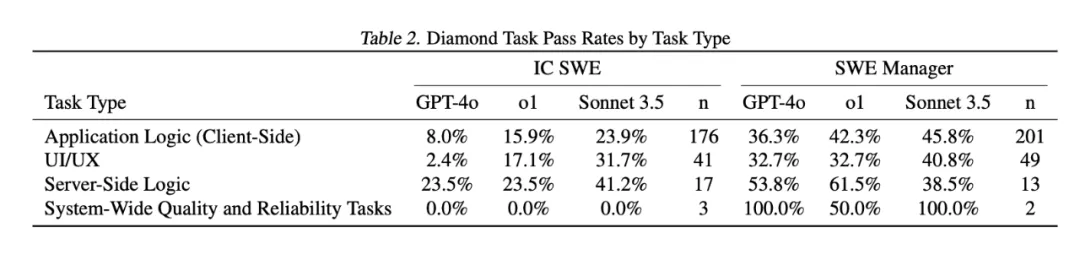
OpenAI罕見的在發表這個測試標準的論文裡承認,Claude 3.5 Sonnet 是比o1和GPT-4o好得多��的模型,這篇論文資料可以得到一些很有趣的結論:
1、Claude 3.5 Sonnet依然是最佳的現實世界軟體工程的程式設計模型選擇,能完成大約40%的任務; 2、大模型在技術管理任務(SWE Manager)的成功率明顯優於獨立開發者任務(IC SWE),所以這是說技術管理者更容易被AI替代? 3、AI在服務端邏輯類任務上的成功率優於前端任何和UI/UX任務(儘管一般人現在會判斷AI程式設計更適合用來寫前端程式碼)。
Claude 3.7 Sonnet = 現實 AI 程式設計能力的又一次突破
所以綜合看這次 Claude 3.7 在 SWE-bench的表現,以及 SWE-Lancer 中OpenAI的評估,說明Sonnet的程式設計能力不僅僅停留在“刷題”,而是真的在現實軟體工程中更有用。
所以,如果你想用 AI 程式設計,不要只看 Codeforces 的分數,要看它在 SWE-bench 和 SWE-Lancer 裡的表現。
現在的結論很簡單:Claude 3.7 Sonnet 是目前 AI 程式設計的最強選擇,遠比任何 Codeforces 刷分高的模型更適合現實開發。
在得出這個結論之後,我們可以再深入看看Claude 3.7 Sonnet有哪些特性,以及他們同步釋出的一款工具Claude Code。
Claude 3.7 Sonnet:推理是一條連續的光譜
Anthropic對模型推理的看法和其他公司(OpenAI、DeepSeek、Grok)都不太一樣,他們更認為模型的推理能力不是0和1之間有涇渭分明的邊界的,而更像是一條連續的光譜。
所以他們沒有推出專門的推理模型,而是推出了一個混合模型(hybrid reasoning model),你可以自由選擇讓模型是否思考,以及…思考多久。在呼叫API的時候,你可以自由限制模型思考的token數,通常來說,更長的思考能獲得更好的表現,最長的思考token可以長達128k,聽起來就挺燒錢的。畢竟這個模型的每百萬輸入token還是需要3美元,百萬輸出token是15美元,比OpenAI的o3-mini和DeepSeek R1都貴了好幾倍。
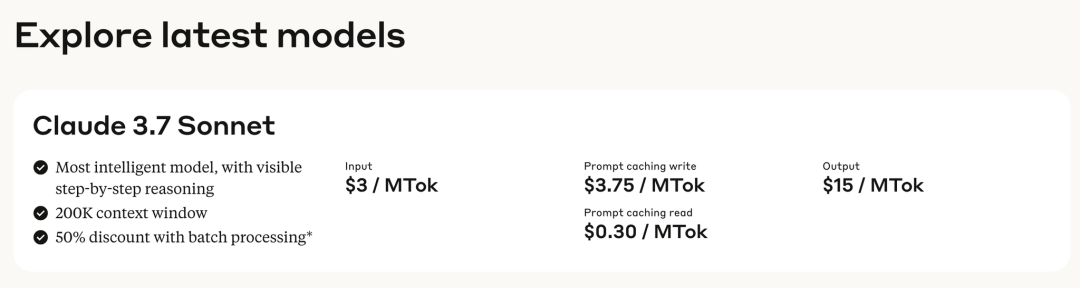
不過現在在C端的產品形態上,還沒體現這種差異,在Claude自己的產品上,你可以透過選擇“Extended”去啟用思考。

在Cursor中,有Claude 3.7 Sonnet和Claude 3.7 Sonnet thinking兩個模型可供選擇。我的建議是,在常規開始一項任務的時候,你選擇常規的Claude 3.7 Sonnet模型即可。在處理bug,或者需要模型幫你做規劃,你希望它能做更多思考時選擇Claude 3.7 Sonnet thinking模型,並且在選擇的時候,你可以提示詞中直白地要求思考更多時間,考慮更多方案即可。
Claude Code:一個不太一樣的 AI 程式設計工具
Claude 3.7 之外,Anthropic 還發布了 Claude Code——一個完全基於終端的 AI 程式碼代理。
如果你用過 Cursor 或者 Copilot,你可能會覺得 AI 程式設計工具應該是 IDE 裡的智慧補全助手。但 Claude Code 走了另一條路:它直接在 命令列 裡執行,可以幫你修改程式碼、提交 Git 變更、修 Bug,甚至管理整個程式碼庫。
說白了,它更像是一個“AI Shell 助手”,而不是一個 IDE 裡的智慧補全工具。
但目前來看,Claude Code 還是一個雛形,它的問題也很明顯:
- 它的許可權管理還不夠完善,AI 直接在你的終端裡操作程式碼,萬一改錯了檔案,可能會造成損失。
- 它的使用者體驗跟 IDE 助手完全不同,需要適應新的工作方式,看起來挺酷,但挺不新手有好的。
所以,你可以試試 Claude Code,但暫時別指望它現在就能完全取代 Cursor。
我很期待Claude 3.7和前段時間OpenAI 的SWE-lancer的釋出能讓各大模型產商們再幹點正事,捲一捲真正有用的現實的軟體工程的能力。
AI距離人類中級工程師的水平又更近了一步,或許我們終於有時間思考那個終極問題:
如果程式碼不再是瓶頸,我們要用怎樣的想象力重新定義軟體?
後�面我會在我的公眾號和B站/YouTube釋出關於Claude 3.7 Sonnet、Claude Code的實操演示影片,歡迎關注。
